Audio-Driven Co-Speech Gesture Video Generation
Advances in Neural Information Processing Systems (NeurIPS), 2022.
Advances in Neural Information Processing Systems (NeurIPS), 2022.
1Multimedia Laboratory, The Chinese University of Hong Kong
2Monash University
3Cornell University 4Shanghai AI Laboratory 5S-Lab, Nanyang Technological University
3Cornell University 4Shanghai AI Laboratory 5S-Lab, Nanyang Technological University
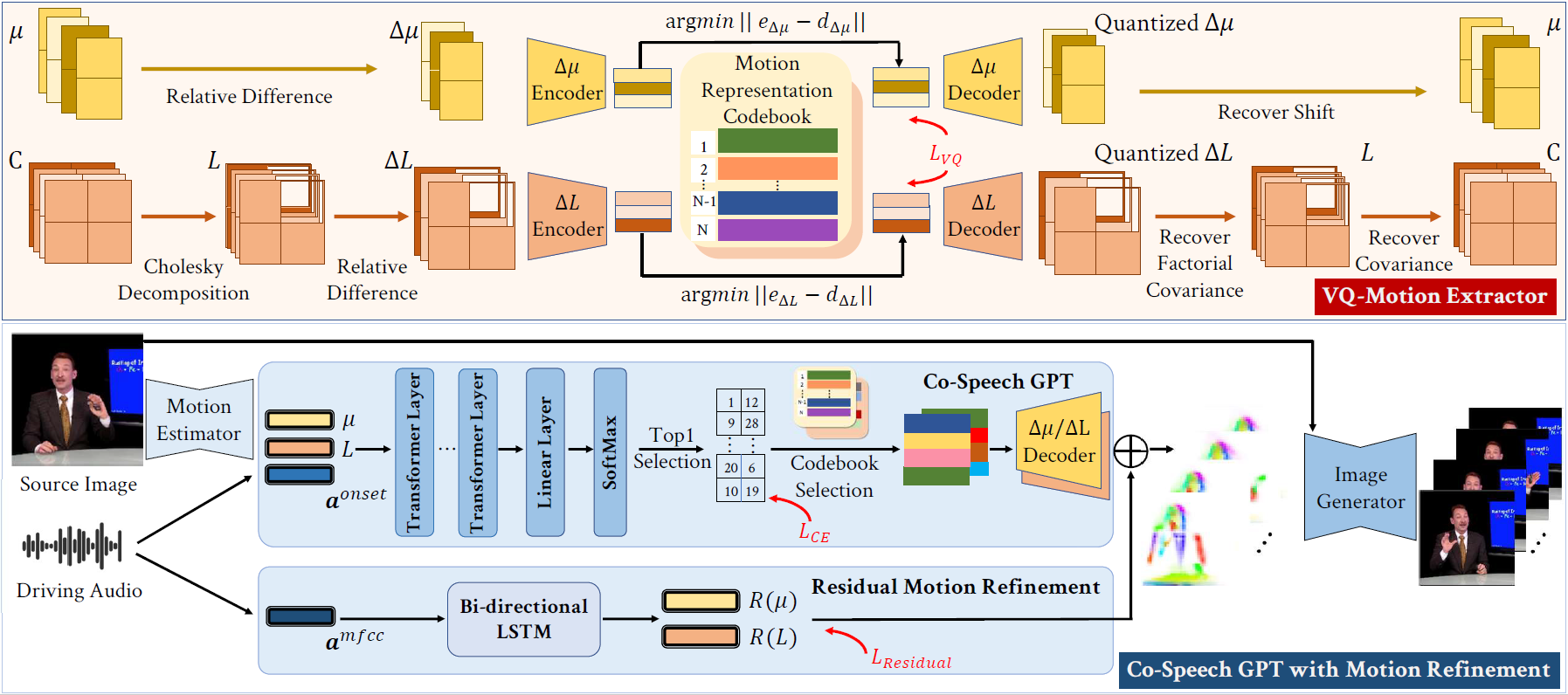



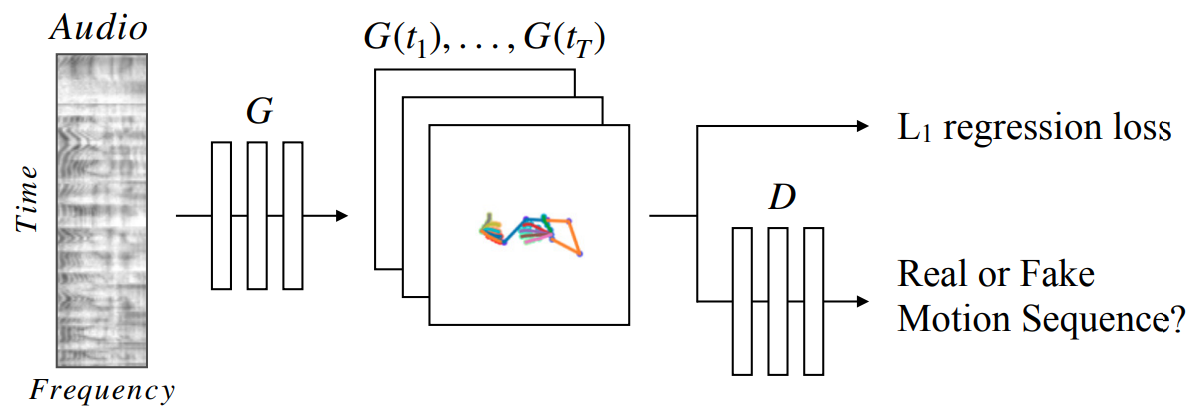
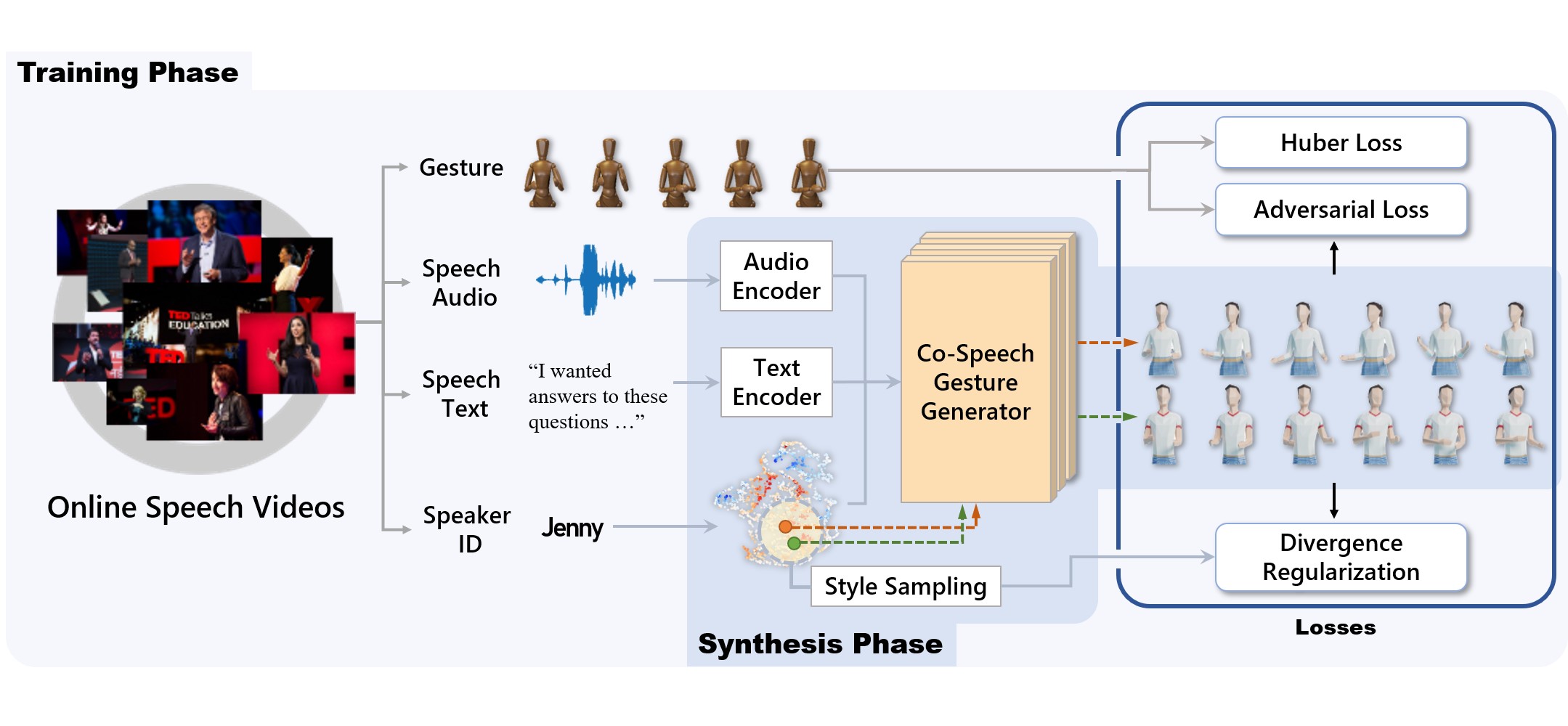
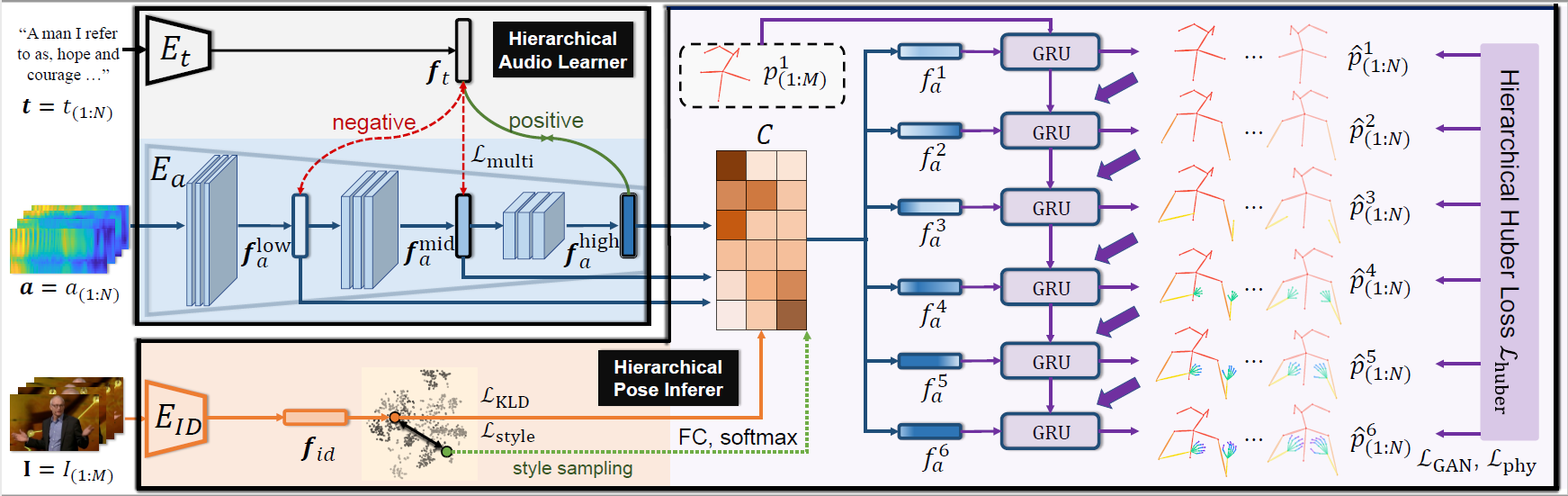
Comment: The first work that utilizes deep learning framework with an adversarial training scheme (GAN) for the task of co-speech gesture generation.