|
NVIDIA Research Santa Clara, CA E-mail / CV / Google Scholar / Github / Twitter / LinkedIn |

|
Full Publications [ Home ] (* indicates equal contribution)

|
Cosmos World Foundation Model Platform for Physical AI
Contributions: Auto-Regressive Foundation Model Pre-Training & Post-Training. (CES'25 Best of AI, Best Overall)
|
|
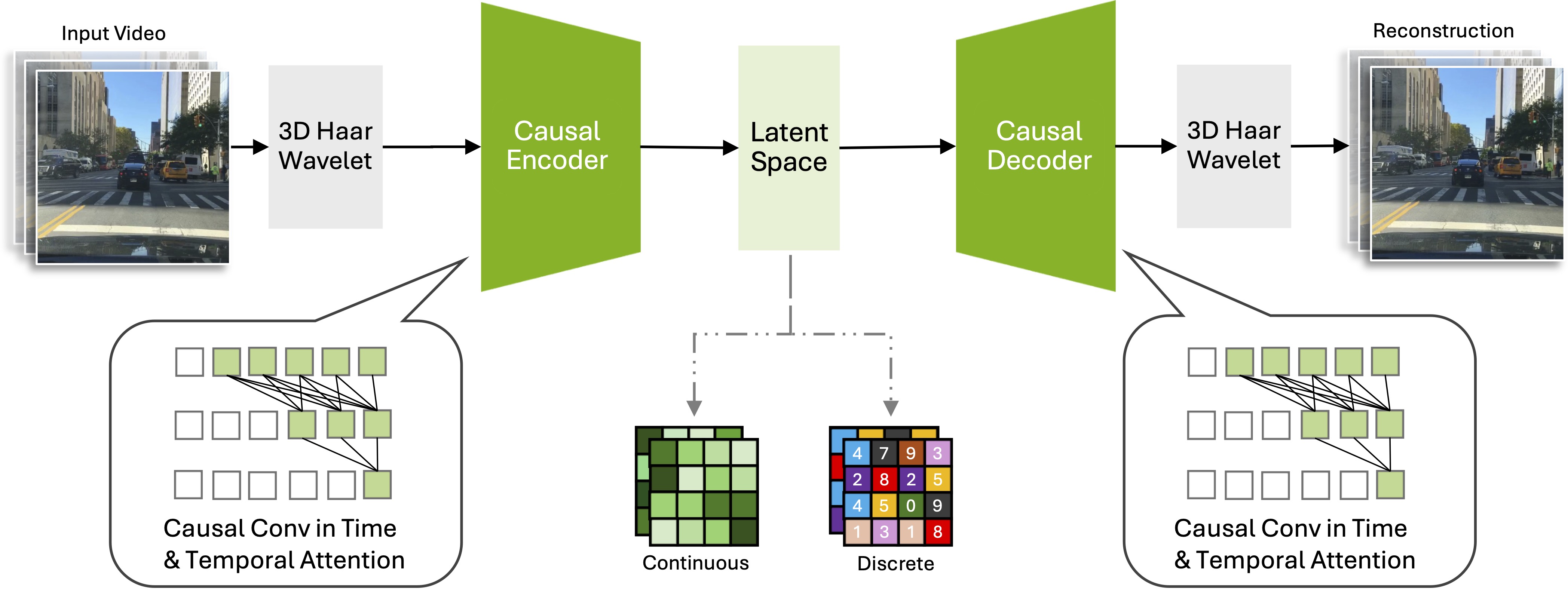
Cosmos Tokenizer: A Suite of Image and Video Neural Tokenizers
Contributions: Continuous/Discrete Image/Video Tokenizers.
|
|
|
Cosmos-Transfer1: World Generation with Adaptive Multimodal Control
Contributions: Adaptive Multi-Modal Control, Data Processing Pipelines, Open-Source Repo.
|

|
Cosmos-Predict2: World Foundation Model Platform for Physical AI
Contributions: Data Processing Pipelines, Captioning, Long Video Generation, Transfer Post-training.
|

|
DPoser-X: Diffusion Model as Robust 3D Whole-body Human Pose Prior
International Conference on Computer Vision (ICCV), 2025. (Oral)
|

|
HMAR: Efficient Hierarchical Masked AutoRegressive Image Generation
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
|
|
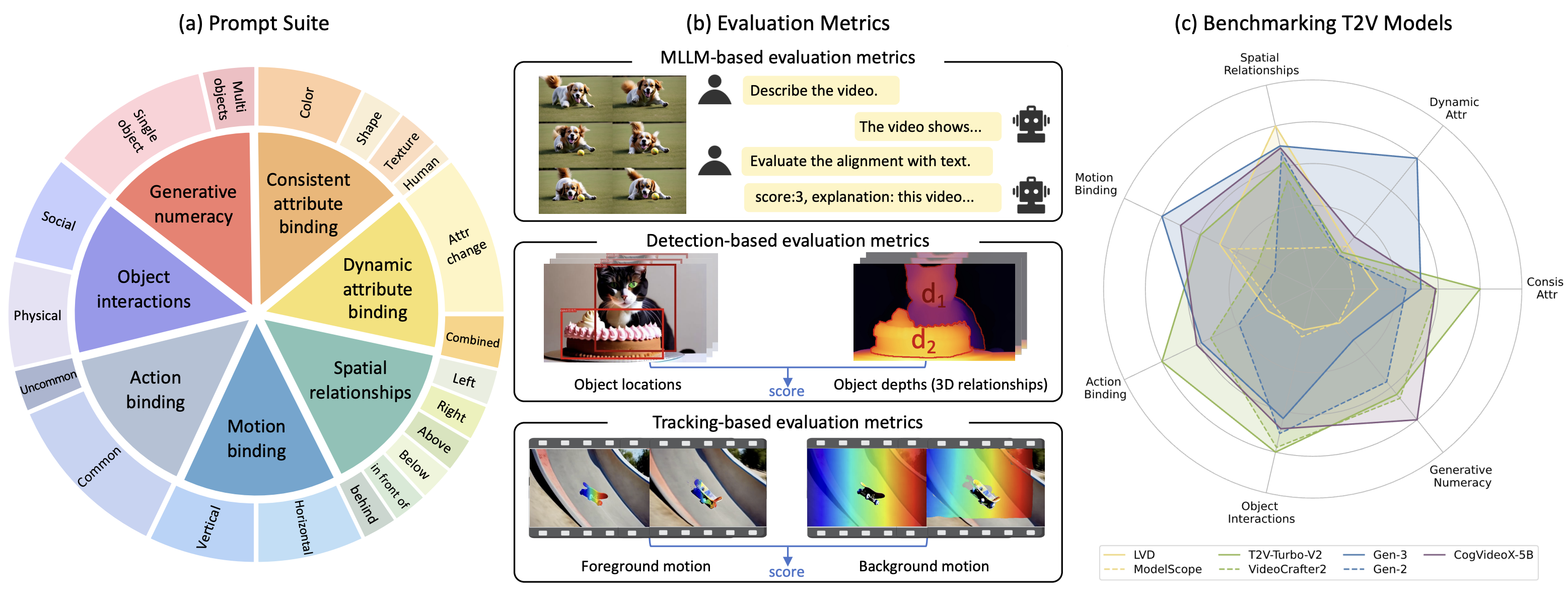
T2V-CompBench: A Comprehensive Benchmark for Compositional Text-to-video Generation
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
|

|
3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
International Conference on Learning Representations (ICLR), 2025.
|
|
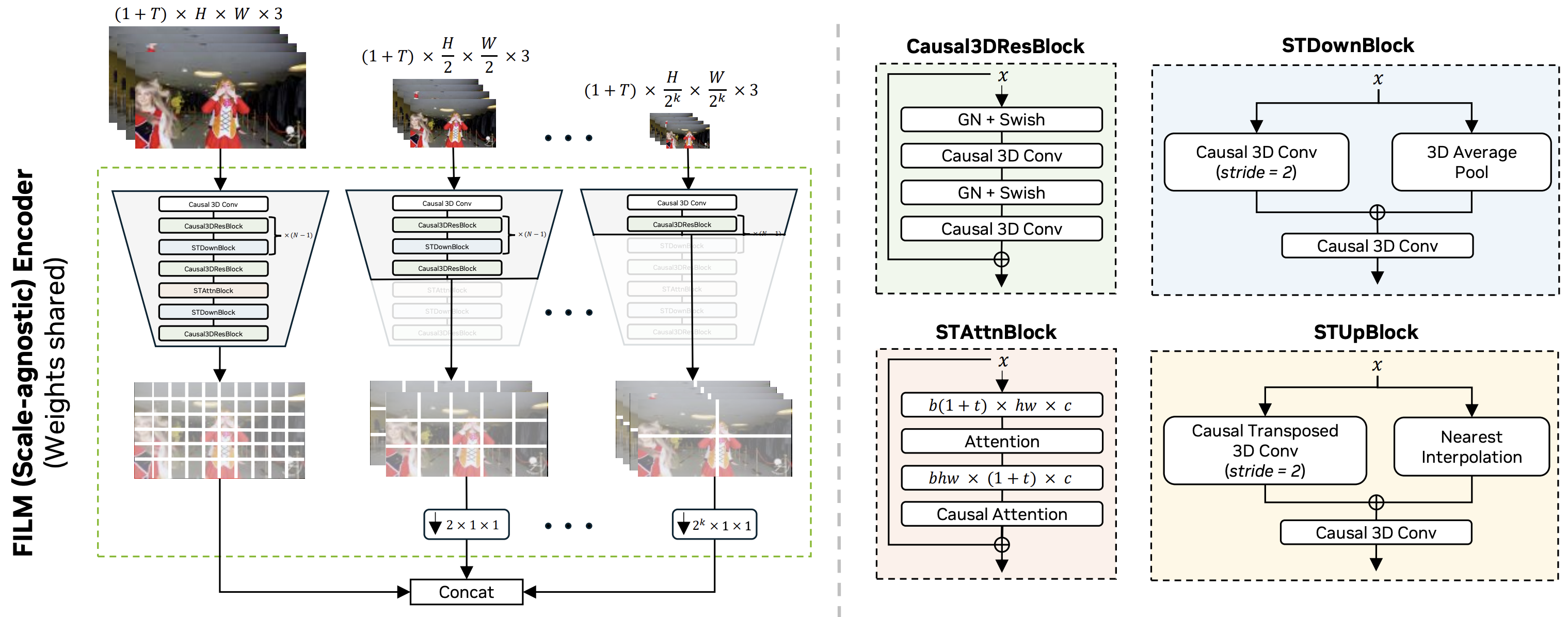
High-Quality Joint Image and Video Tokenization with Causal VAE
International Conference on Learning Representations (ICLR), 2025.
|

|
Accelerating Auto-regressive Text-to-Image Generation with Training-free Speculative Jacobi Decoding
International Conference on Learning Representations (ICLR), 2025.
|

|
EdgeRunner: Auto-regressive Auto-encoder for Artistic Mesh Generation
International Conference on Learning Representations (ICLR), 2025.
|

|
MotionCraft: Crafting Whole-Body Motion with Plug-and-Play Multimodal Controls
AAAI Conference on Artificial Intelligence (AAAI), 2025.
|

|
TC4D: Trajectory-Conditioned Text-to-4D Generation
European Conference on Computer Vision (ECCV), 2024.
|

|
BrushNet: A Plug-and-Play Image Inpainting Model with Decomposed Dual-Branch Diffusion
European Conference on Computer Vision (ECCV), 2024.
|
|
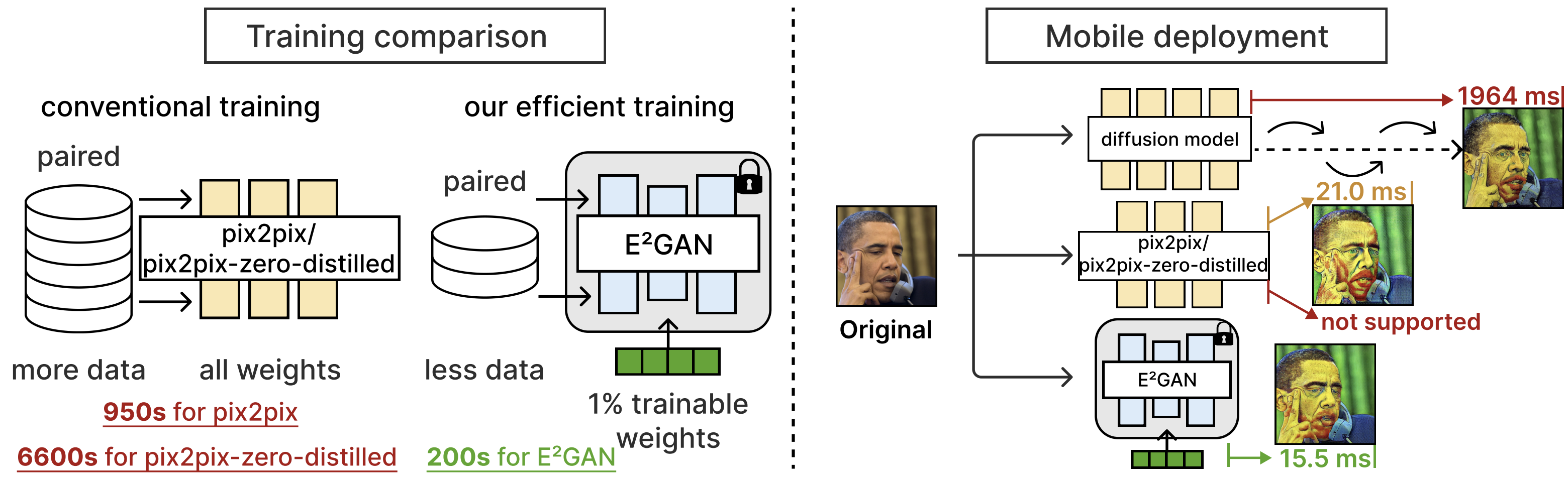
E2GAN: Efficient Training of Efficient GANs for Image-to-Image Translation
International Conference on Machine Learning (ICML), 2024.
|

|
HumanGaussian: Text-Driven 3D Human Generation with Gaussian Splatting
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. (Highlight, Top 2.8%)
|

|
TextCraftor: Your Text Encoder Can be Image Quality Controller
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024.
|

|
HyperHuman: Hyper-Realistic Human Generation with Latent Structural Diffusion
International Conference on Learning Representations (ICLR), 2024. (Review Score 6, 6, 8, 10, Top 1.6%, Rank)
|
|
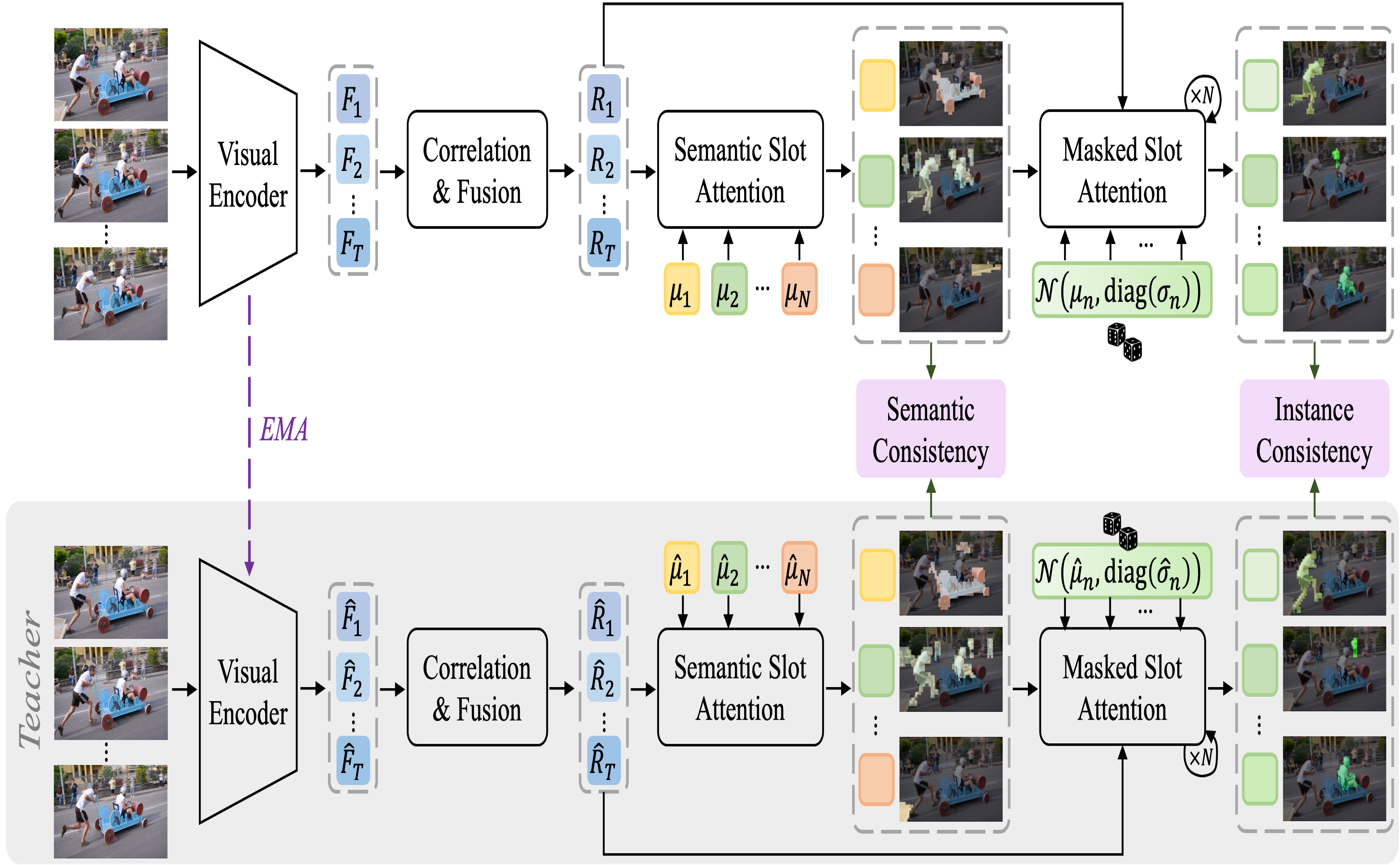
Semantics Meets Temporal Correspondence: Self-supervised Object-centric Learning in Videos
International Conference on Computer Vision (ICCV), 2023.
|
|
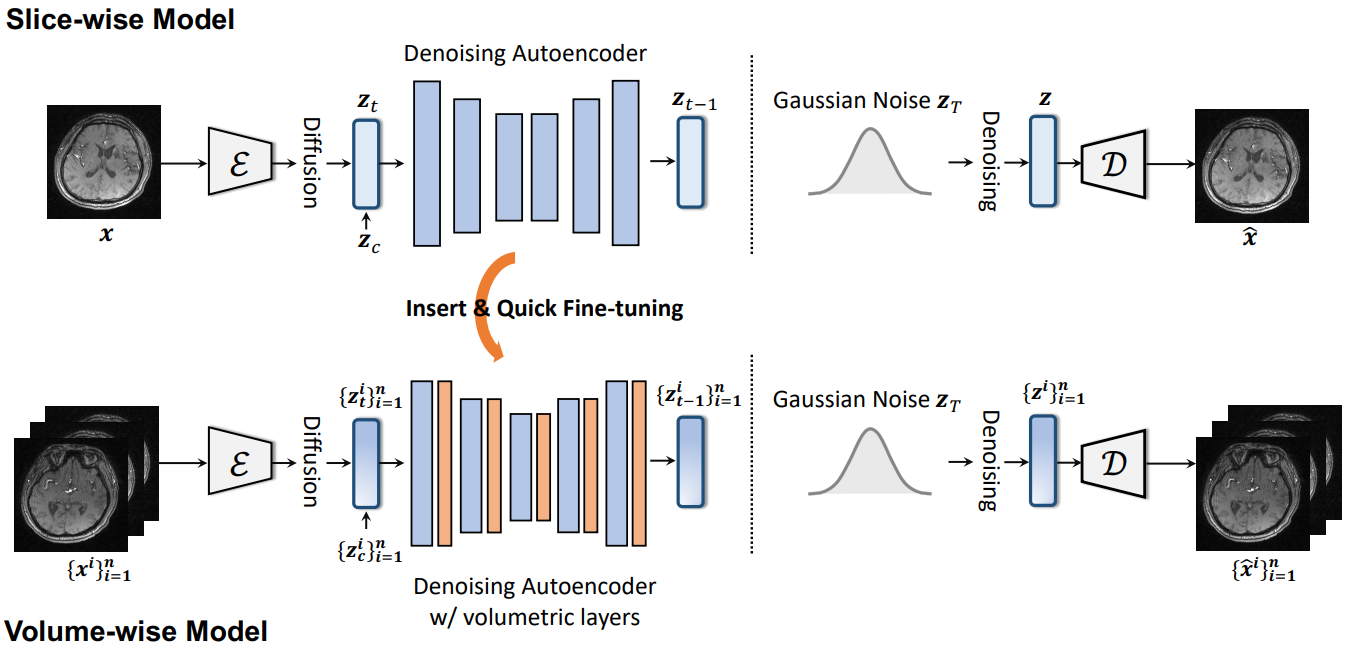
Make-A-Volume: Leveraging Latent Diffusion Models for Cross-Modality 3D Brain MRI Synthesis
Medical Image Computing and Computer Assisted Intervention (MICCAI), 2023.
|
|
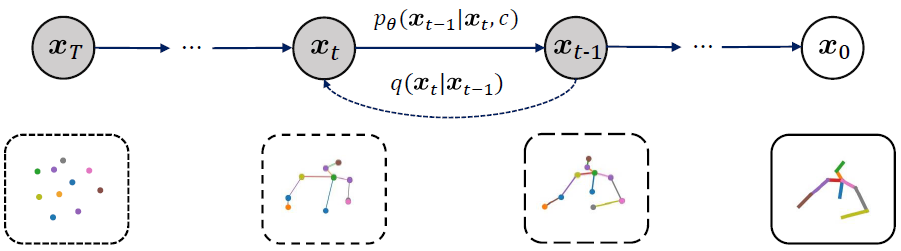
Taming Diffusion Models for Audio-Driven Co-Speech Gesture Generation
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
|
|
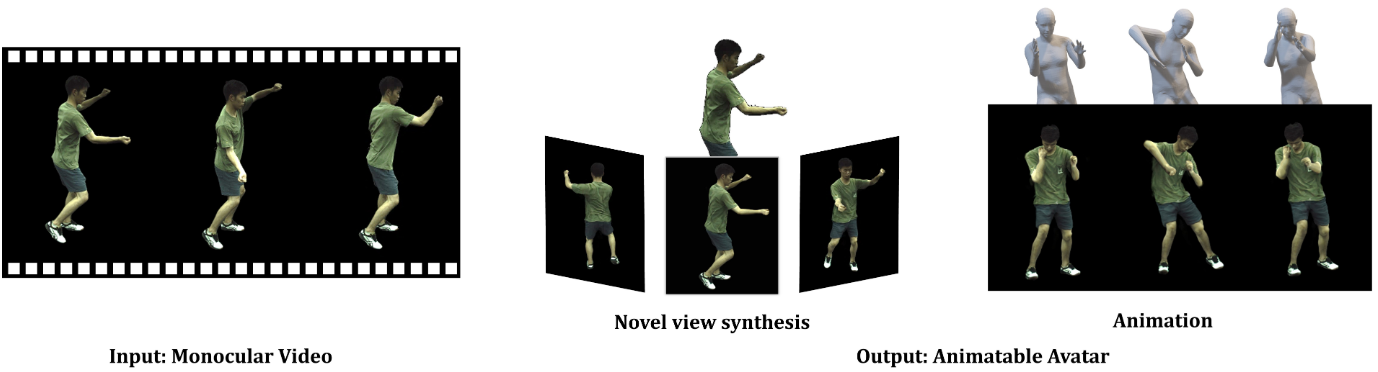
MonoHuman: Animatable Human Neural Field from Monocular Video
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
|
|
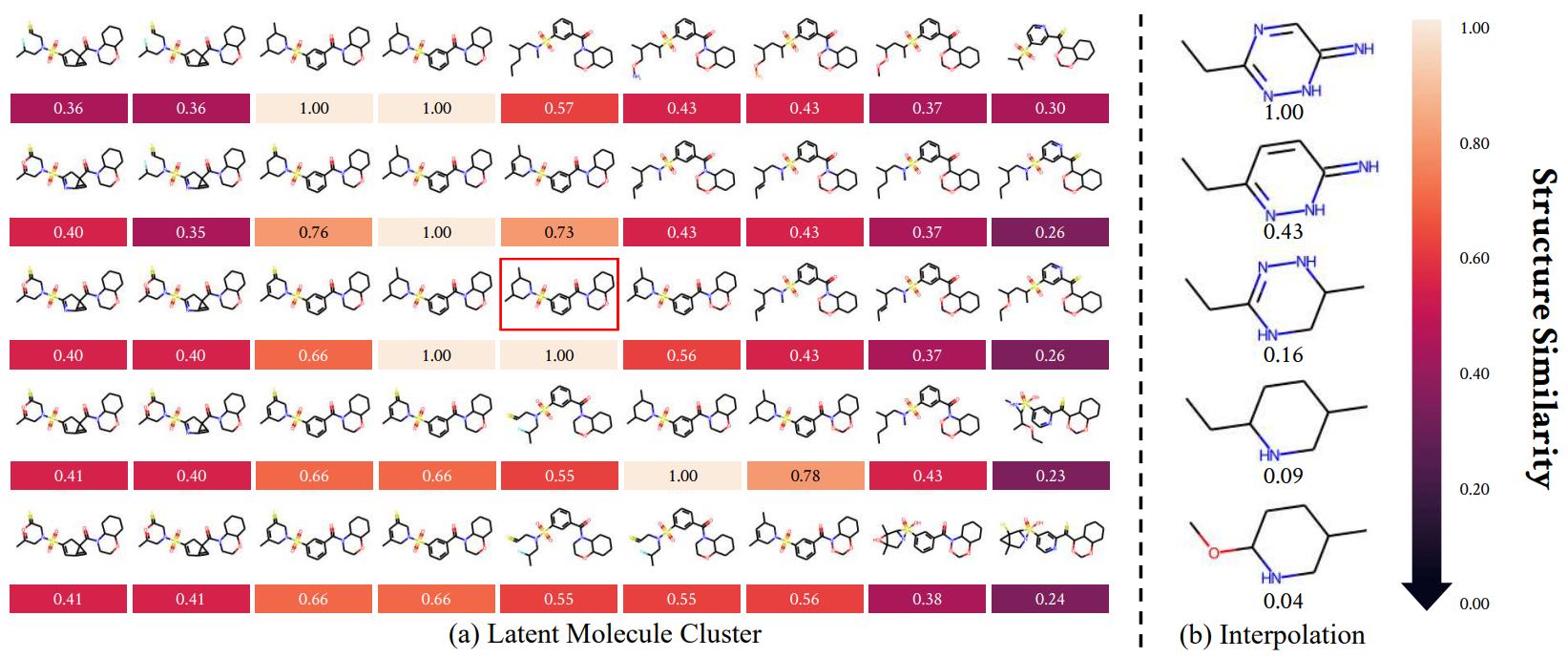
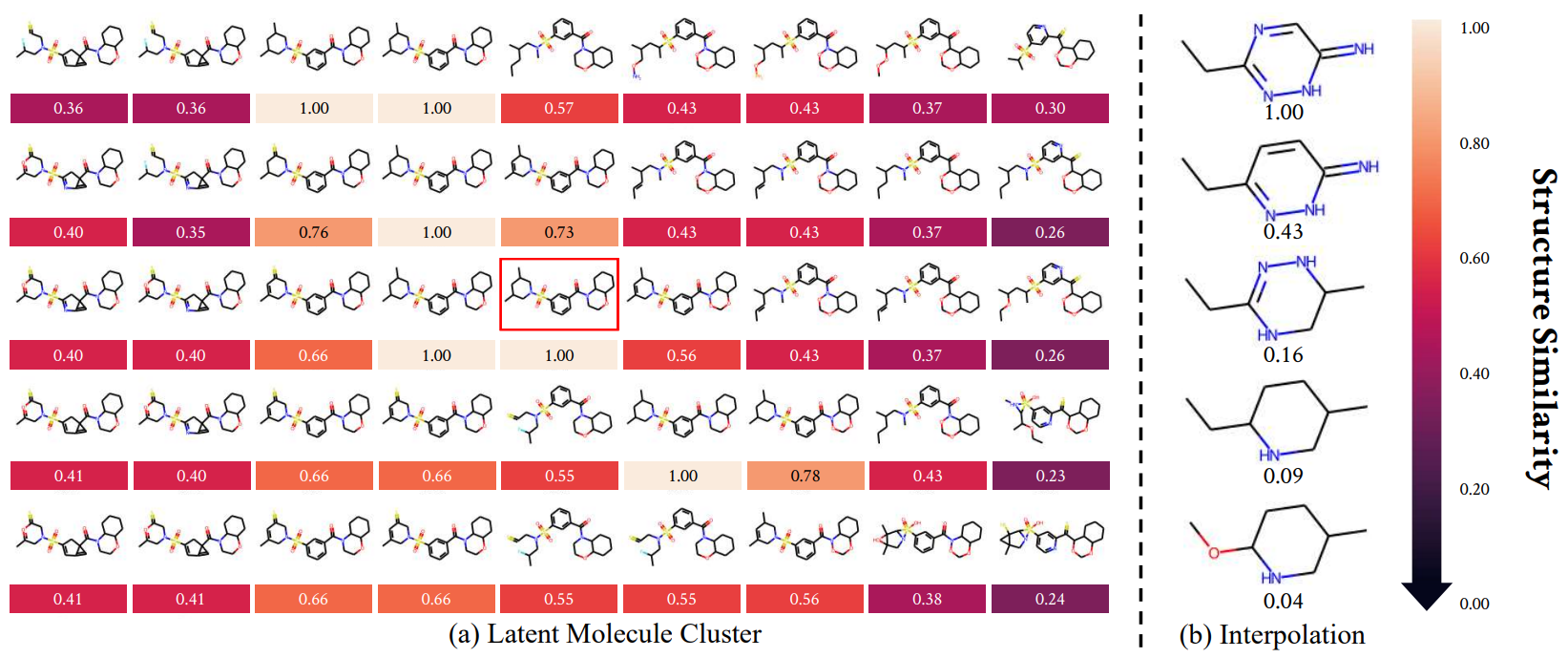
ChemSpacE: Interpretable and Interactive Chemical Space Exploration
Transactions on Machine Learning Research (TMLR), 2023.
|
|
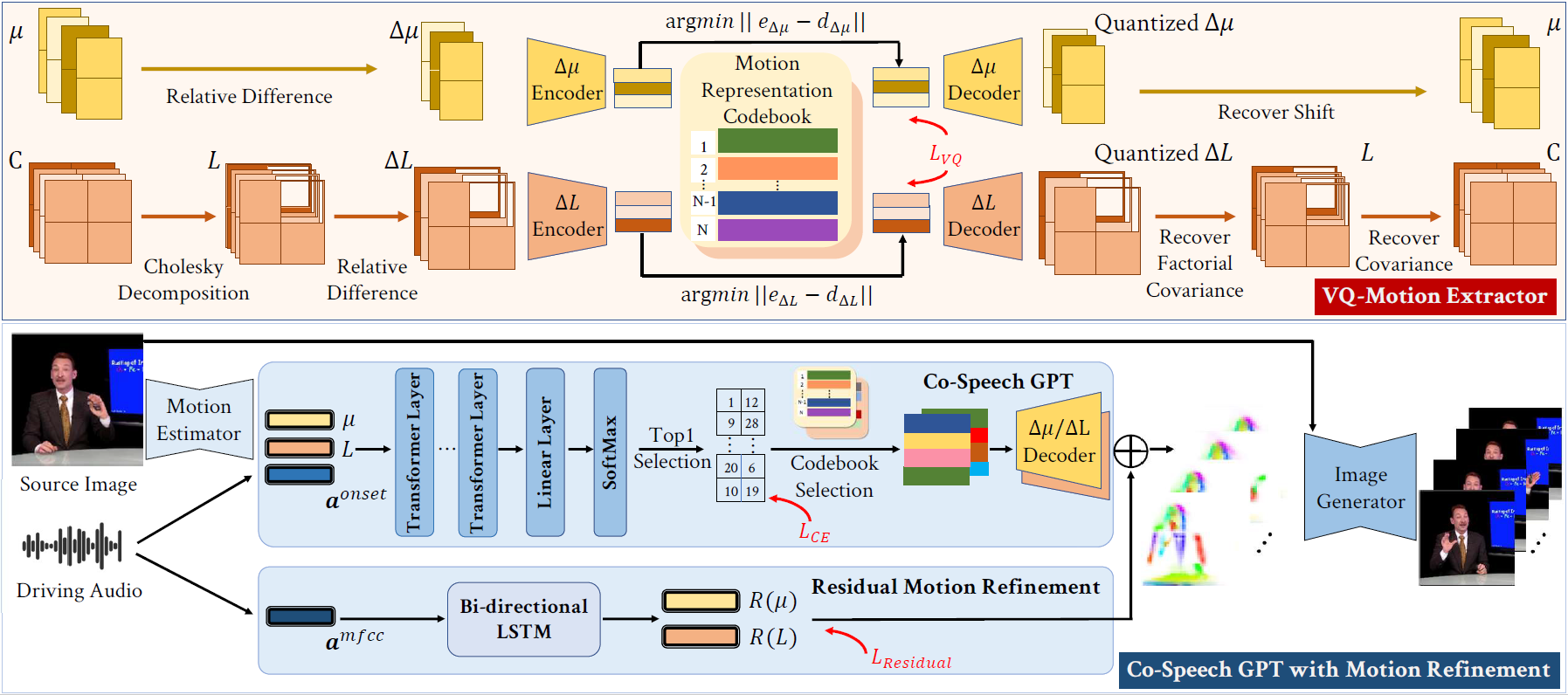
Audio-Driven Co-Speech Gesture Video Generation
Advances in Neural Information Processing Systems (NeurIPS), 2022. (Spotlight, Top 5%)
|
|
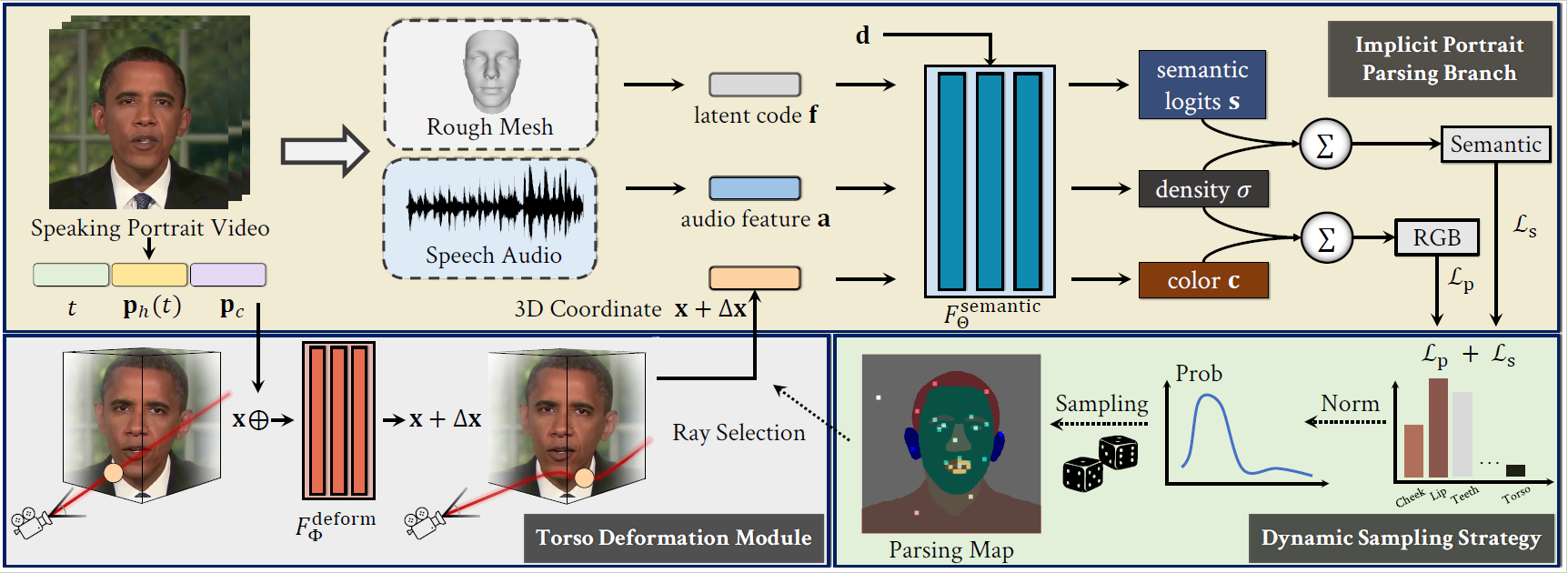
Semantic-Aware Implicit Neural Audio-Driven Video Portrait Generation
European Conference on Computer Vision (ECCV), 2022. (Oral, Top 2.7%)
|
|
ChemSpacE: Toward Steerable and Interpretable Chemical Space Exploration
International Conference on Learning Representations (ICLR) Workshop, 2022.
Also appears at ELLIS 2021 MLMD Workshop. (Oral, Top 5%)
|
|
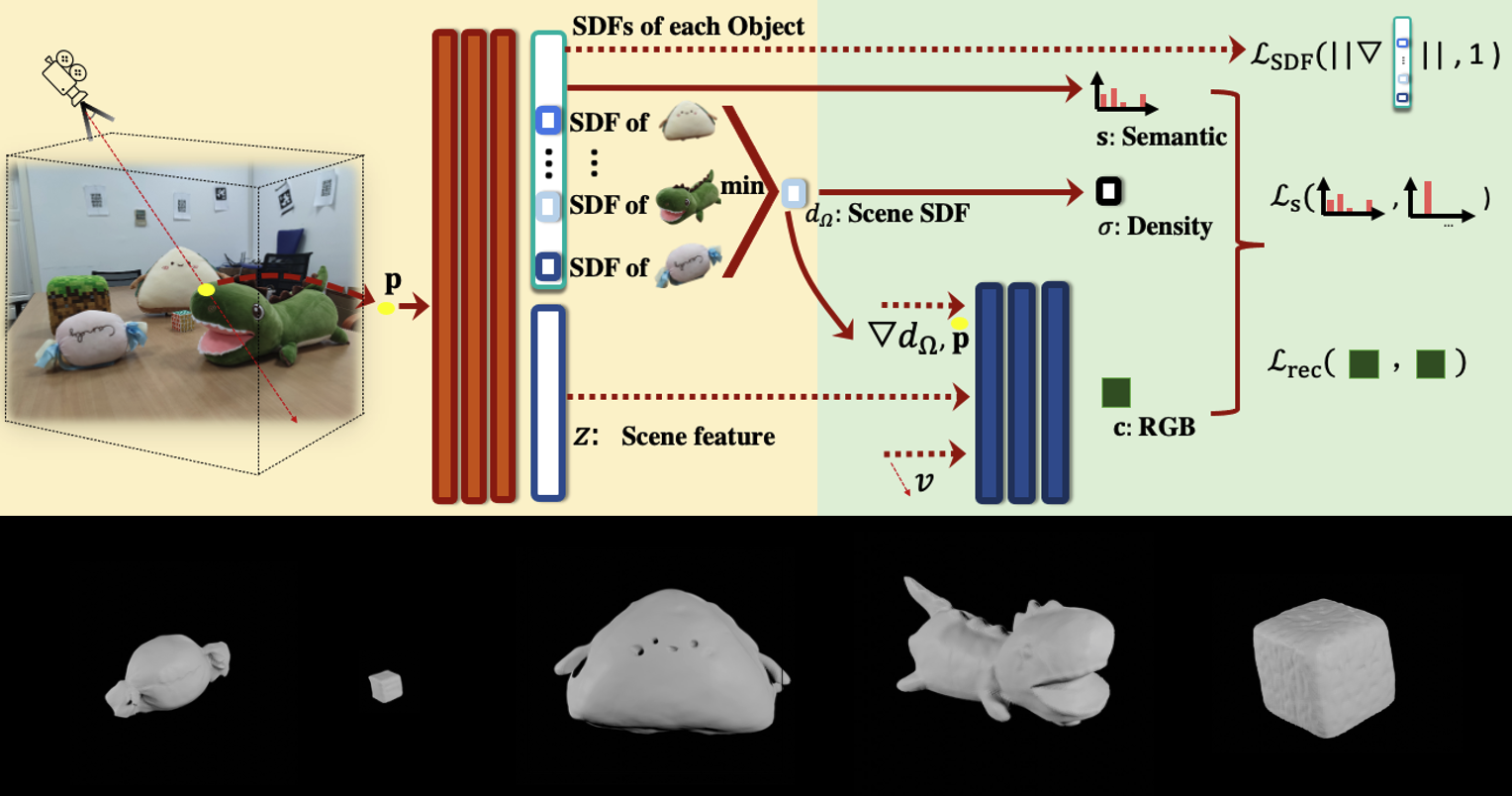
Object-Compositional Neural Implicit Surfaces
European Conference on Computer Vision (ECCV), 2022.
|
|
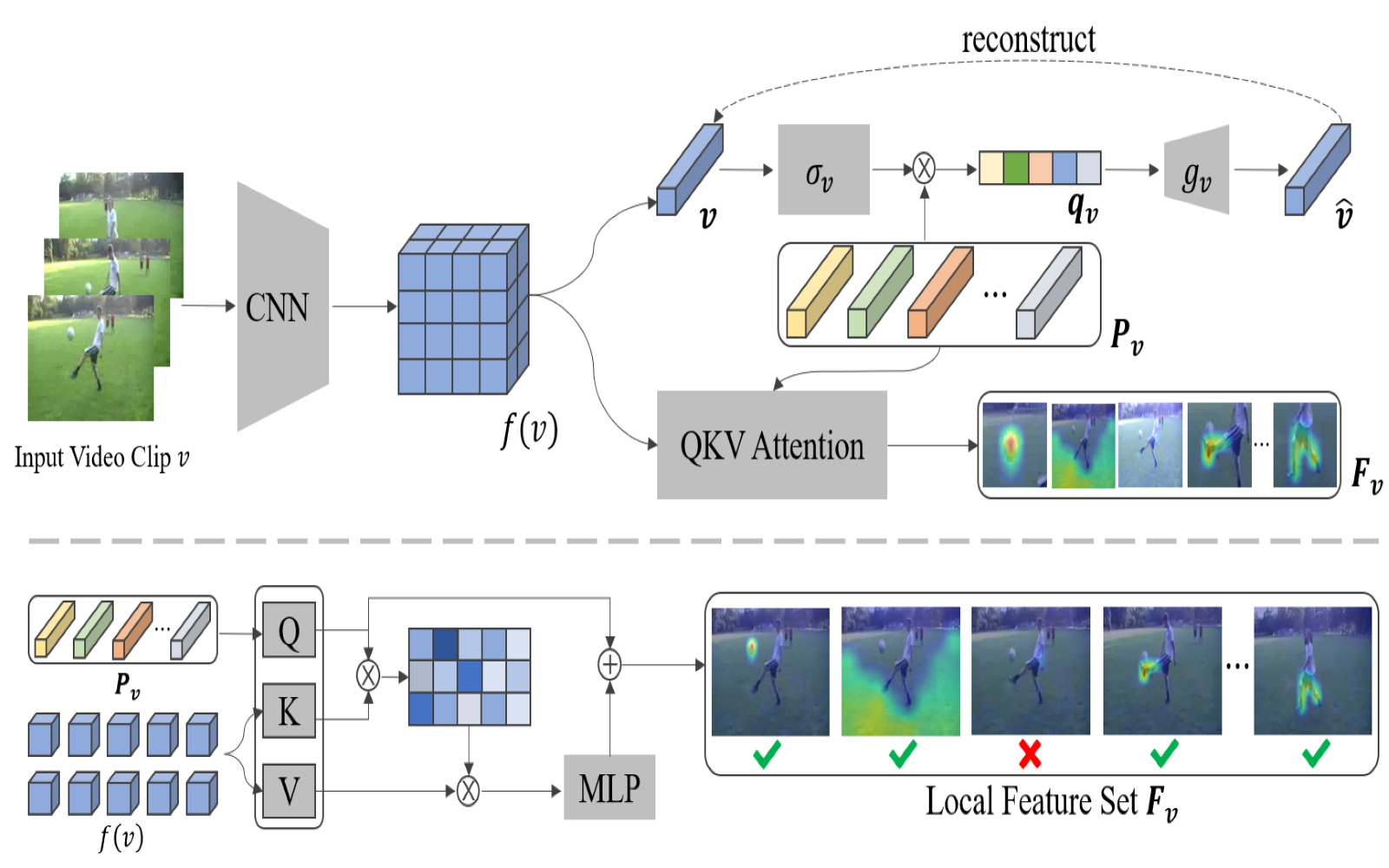
Static and Dynamic Concepts for Self-supervised Video Representation Learning
European Conference on Computer Vision (ECCV), 2022.
|
|
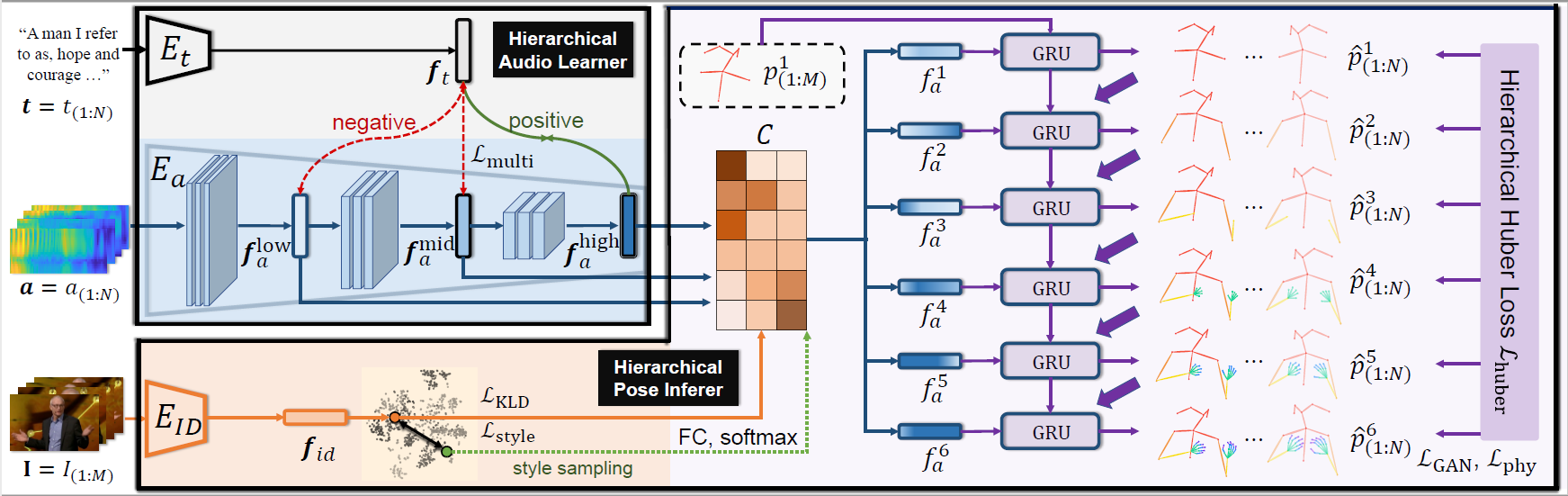
Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
Also appears at CVPR 2022 Sight and Sound Workshop. [5-min Invited Talk] (link)
|

|
Visual Sound Localization in the Wild by Cross-Modal Interference Erasing
AAAI Conference on Artificial Intelligence (AAAI), 2022.
|
|
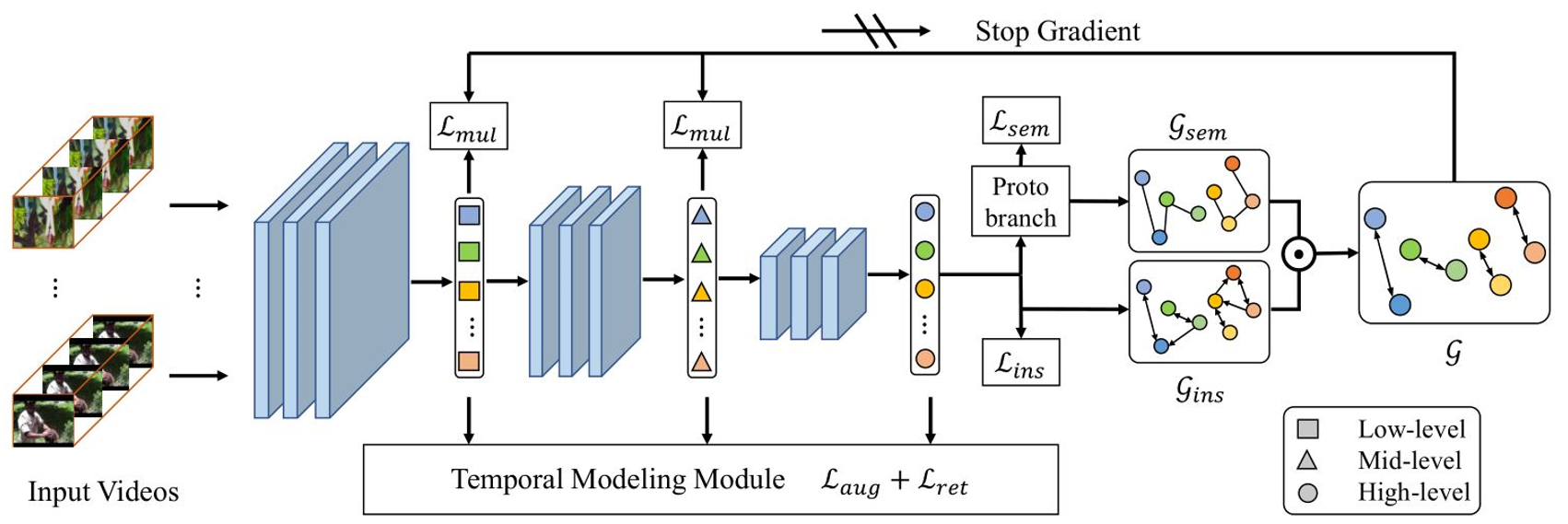
Enhancing Self-supervised Video Representation Learning via Multi-level Feature Optimization
International Conference on Computer Vision (ICCV), 2021.
|
|
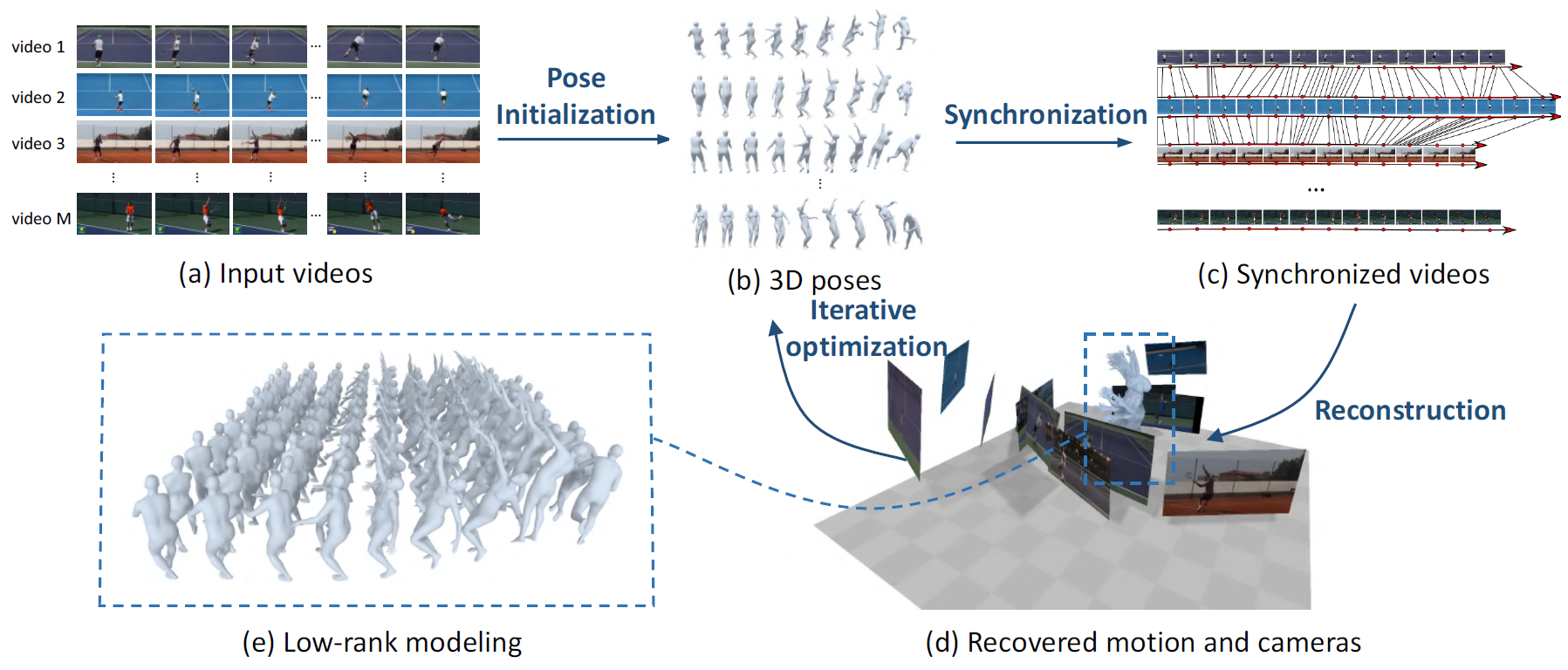
Motion Capture from Internet Videos
European Conference on Computer Vision (ECCV), 2020. (Oral, Top 2%)
|